Azure Cosmos DB Partitioning
- Print
- DarkLight
- PDF
Azure Cosmos DB Partitioning
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
#ServerlessTips - Azure Cosmos DB
Author: Steef-Jan Wiggers Azure MVP
Partitioning is a crucial feature of Cosmos DB that enables this global distribution and horizontal scalability.
In Cosmos DB, data is partitioned based on a partition key, a property of the data that determines how it is distributed across different partitions. Each partition is a unit of scale and is stored on a separate physical server. The partition key is used to determine which partition a piece of data belongs to, and the data within each partition is stored in a sorted order based on the partition key.
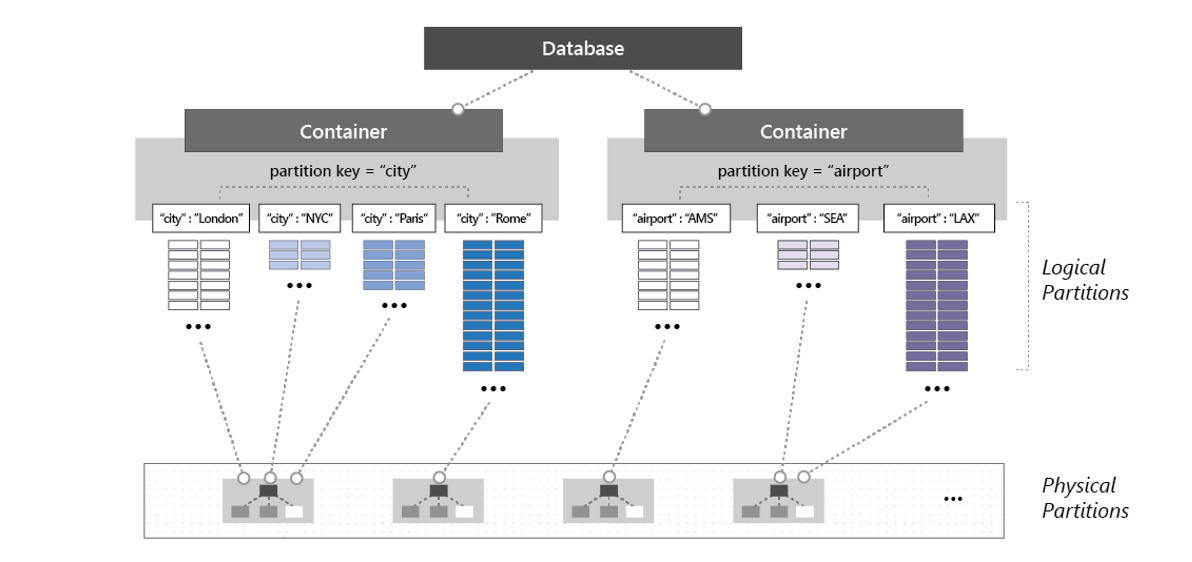
Source: https://learn.microsoft.com/en-us/azure/cosmos-db/set-throughput
When a partition becomes too large to handle the read and write requests, Cosmos DB automatically splits the partition into two smaller partitions, a process called horizontal partitioning. This allows Cosmos DB to scale horizontally and handle increasing read and write loads without interruption to the service.
Partitioning in Cosmos DB also allows for high data availability, as each partition is replicated across multiple regions, providing built-in redundancy and failover capabilities.
When designing your data model in Cosmos DB, choosing a partition key that will distribute the data evenly across the partitions is crucial to ensure that the data can be distributed and scaled effectively. This can be achieved by selecting a partition key with a high cardinality (many unique values) and partitioning data with a high access rate together.
Was this article helpful?