Azure SQL Database: Optimize costs using Elastic Pools
- Print
- DarkLight
- Download PDF
Azure SQL Database: Optimize costs using Elastic Pools
- Print
- DarkLight
- Download PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
#ServerlessTips - Azure Cost Management
Author: Tidjani Belmansour Azure MVP
This article is part of a series on the topic of Cloud Cost Optimization.
While Cloud Cost Optimization requires robust monitoring, there exist some best practices that we’ll share with you throughout this series.
In today’s article, we’ll see how SQL Elastic Pools can help you optimize Azure SQL databases costs.
I see too many customers using Azure SQL Database and still have multiple databases with their own SKU. While there’s absolutely no problem with this approach from an operational perspective, it might not be the most cost-effective solution.
Think about it: you have multiple databases, each with a different SKU that you pay for even though you are not using it to its full potential.
Let’s face it: many of us still provision capacity (aka, choose a SKU) according to the maximum expected load on the database, and most of the time, this approach results in a waste of capacity (and money) as you can see on this figure:
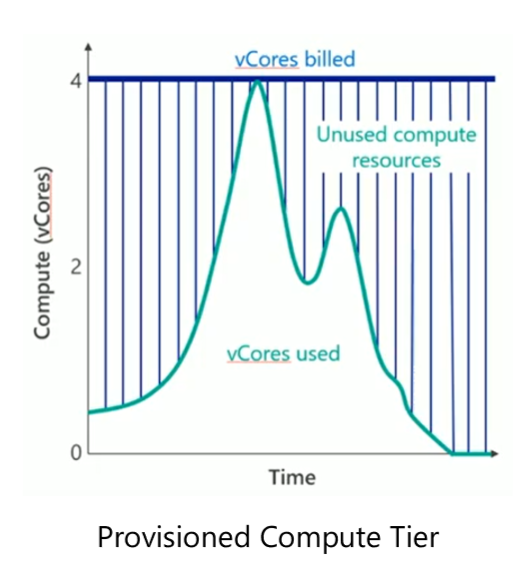
However, most often, these multiple databases have different load patterns. This means that they don’t consume resources at the same time and at different levels, as shown in this figure:
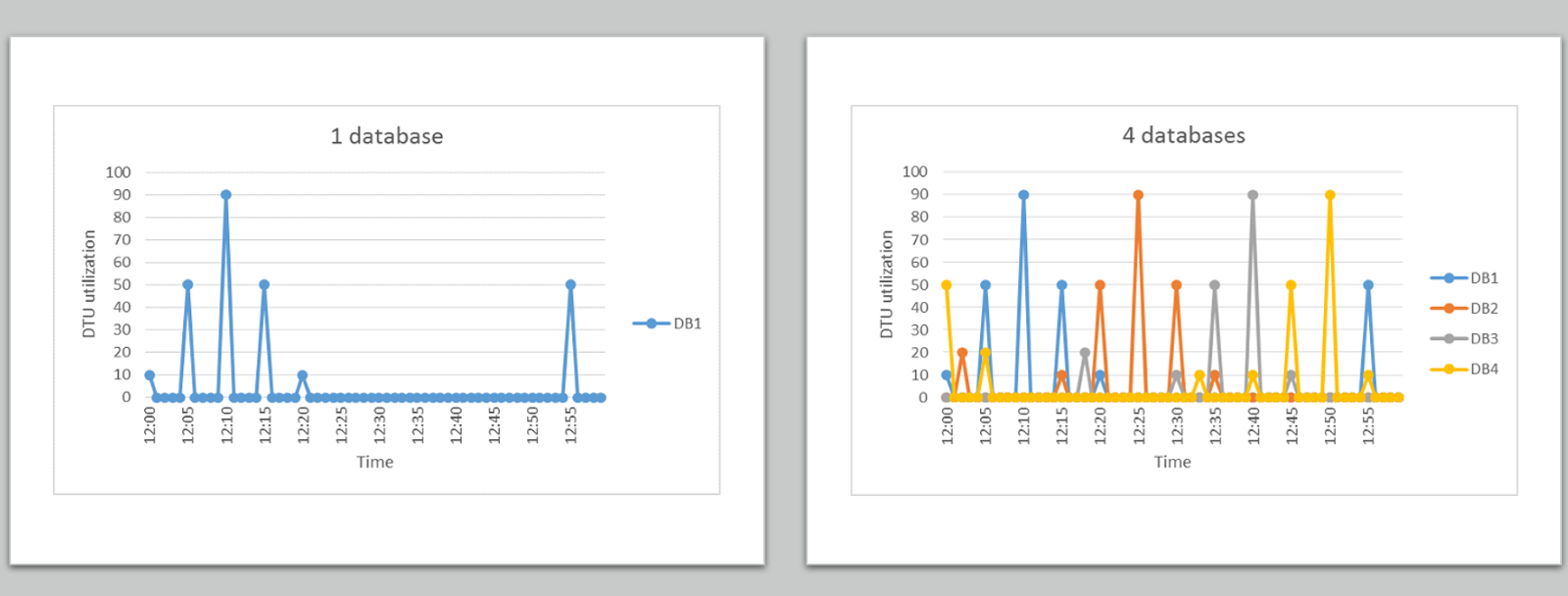
For example, note that at 12:15 the amount of DTU utilized is 60 (50 used by DB1 + 10 used by DB2). Also note that, at any point in time, the amount of DTU utilized does not exceed the amount of DTU provisioned (which is 100).
And that EXACTLY the use case for an Elastic Pool: have these databases share a single pool of resources, hence optimizing costs while fulfilling demand.
Creating a SQL Elastic Pool
In the Azure Portal search bar, look for “Elastic Pool”:
The creation wizard will ask us to select:
- The SKU of the Elastic Pool: An Elastic Pool SKU can either be DTU-based or vCore-based.
- The Server on which it will run: if your databases are currently on multiple servers, you’ll need to replicate the IP Firewall rules and the SQL authentication account.
- We can use Hybrid Benefits (if we’re eligible to it) and save about 35% of the cost.
The “Databases” tab allows us to add our existing databases to the Elastic Pool we’re about to create:
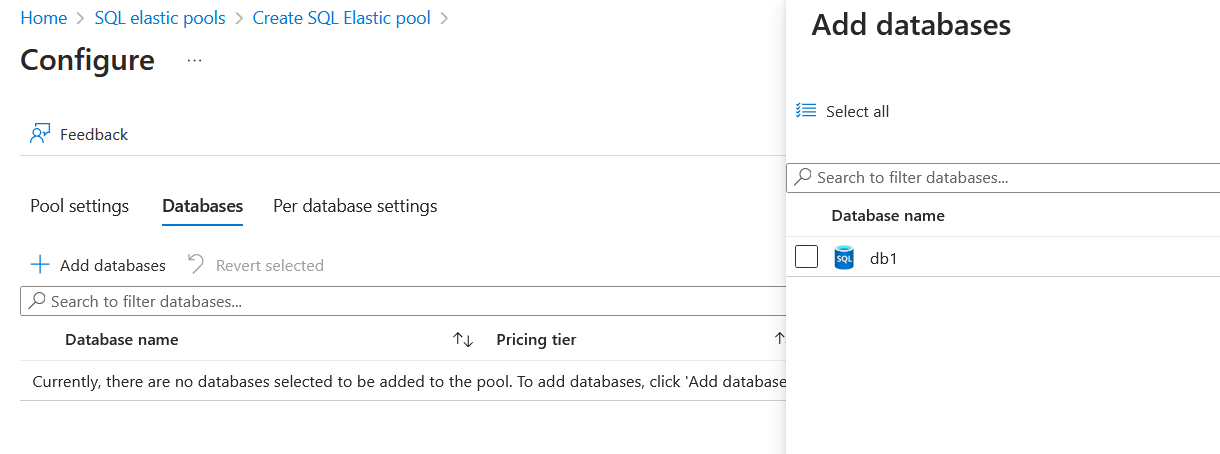
There are some interesting things to note here:
- No matter whether the Elastic Pool is DTU-based or vCPU-based, we can add DTU- and vCPU-based databases to it.
- We can only add databases to the Elastic Pool from the same server on which the Elastic Pool is running.
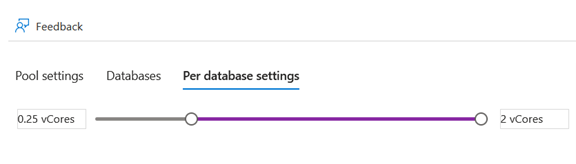
The “Per database settings” tab allows us to set the minimum and maximum vCores that one database can use:
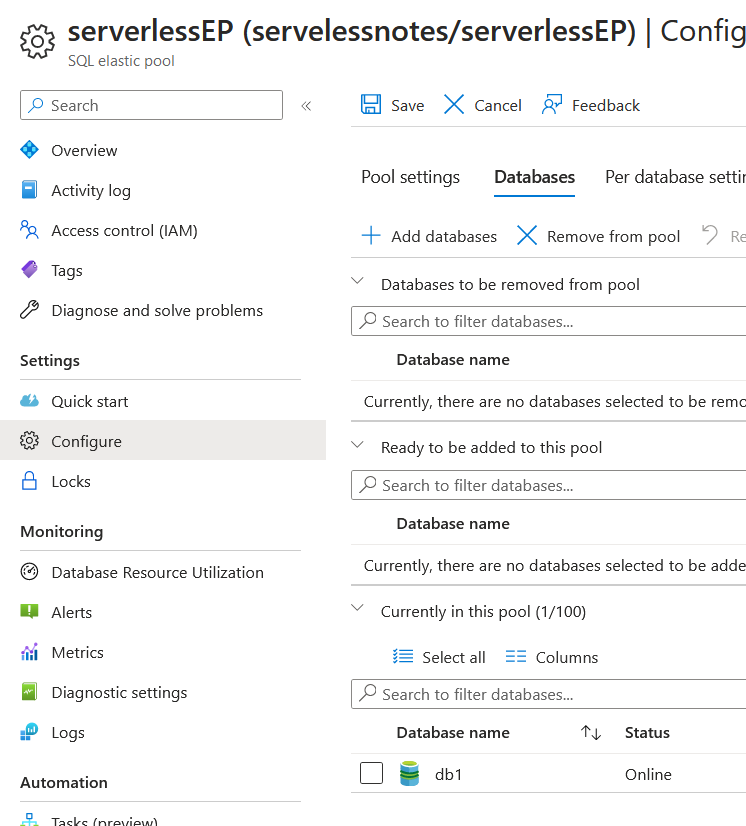
Once the Elastic Pool is created, we can go to the “Configure” section to either add or remove databases to/from the pool:
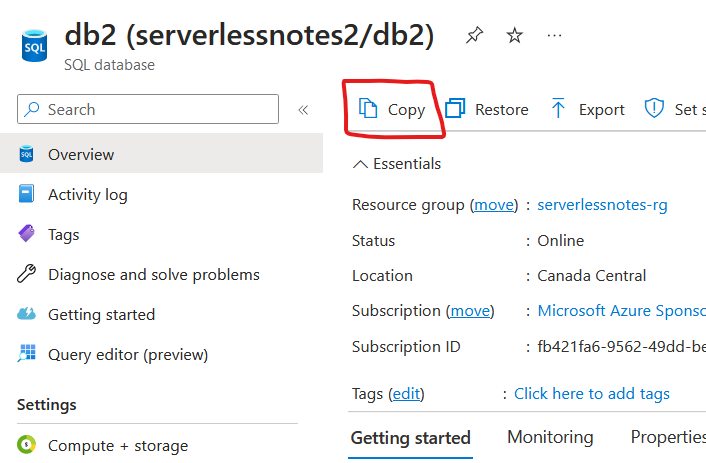
If the database we want to add is not listed, it means that it is not on the same server as the Elastic Pool. In that case, go to the database you want to add to the Elastic Pool and click on “Copy”:
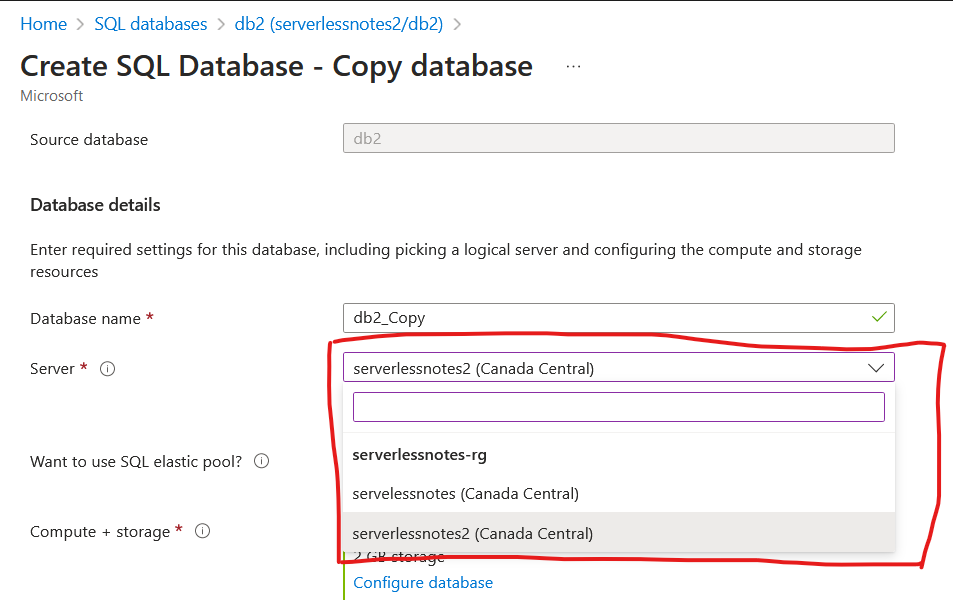
There, you’ll be able to make a copy of it onto the same server as the Elastic Pool:
Once done, you can go back to the “Configure” section and add that database to the Elastic Pool. You may then want to delete the database from the original server.
And there you have it! You can now add SQL Elastic Pool to your Cost Optimization Strategy. Just keep in mind that Elastic Pool fits in a scenario where you have multiple databases with different usage patterns.

Was this article helpful?